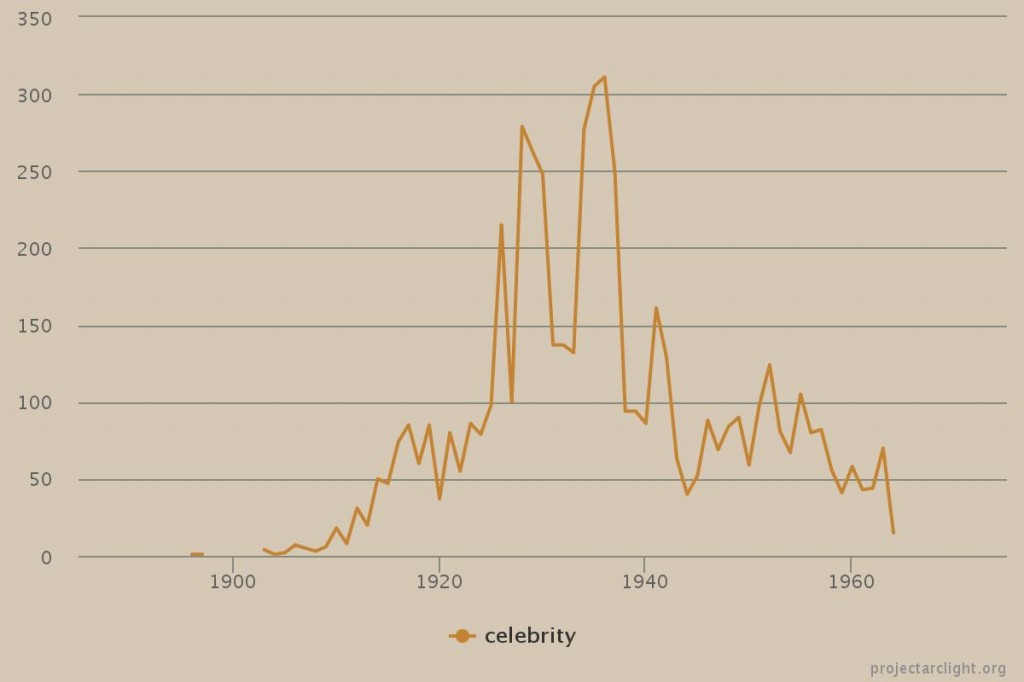
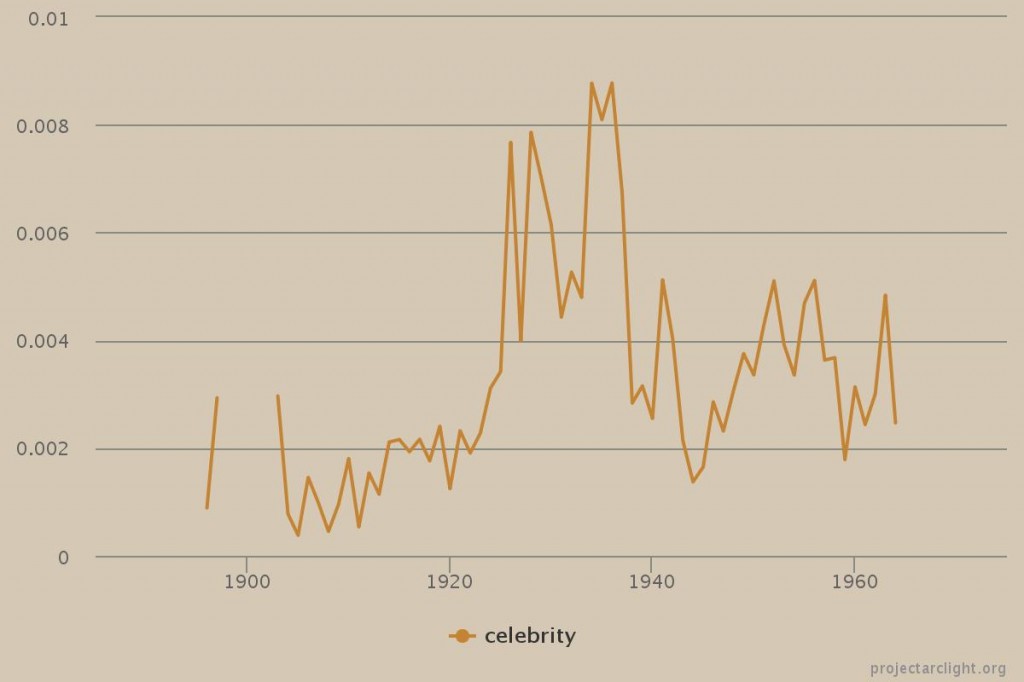
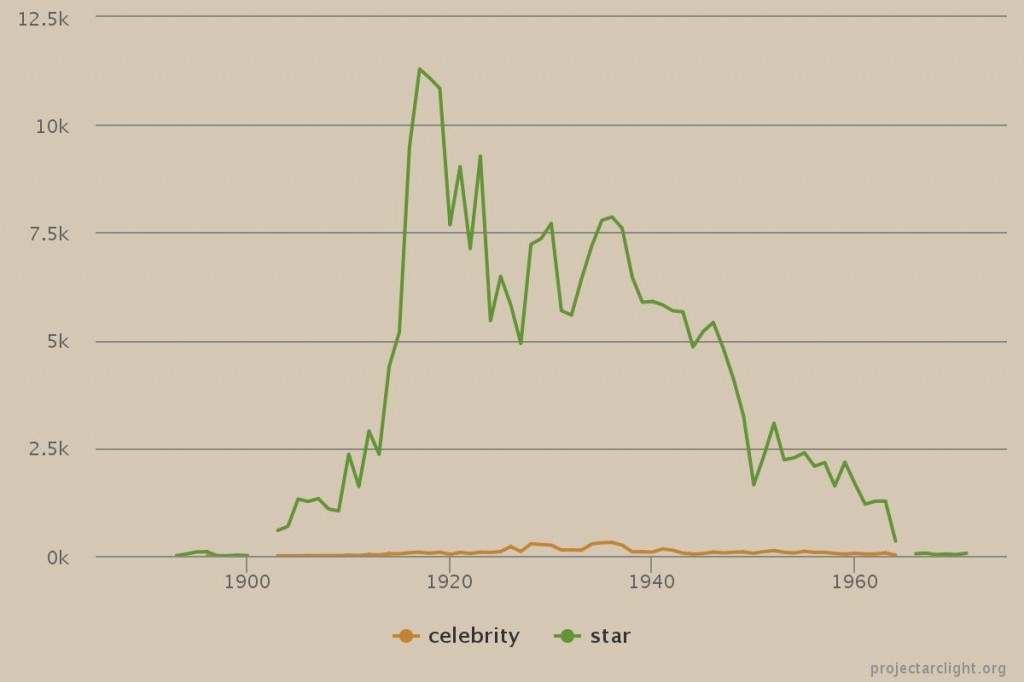
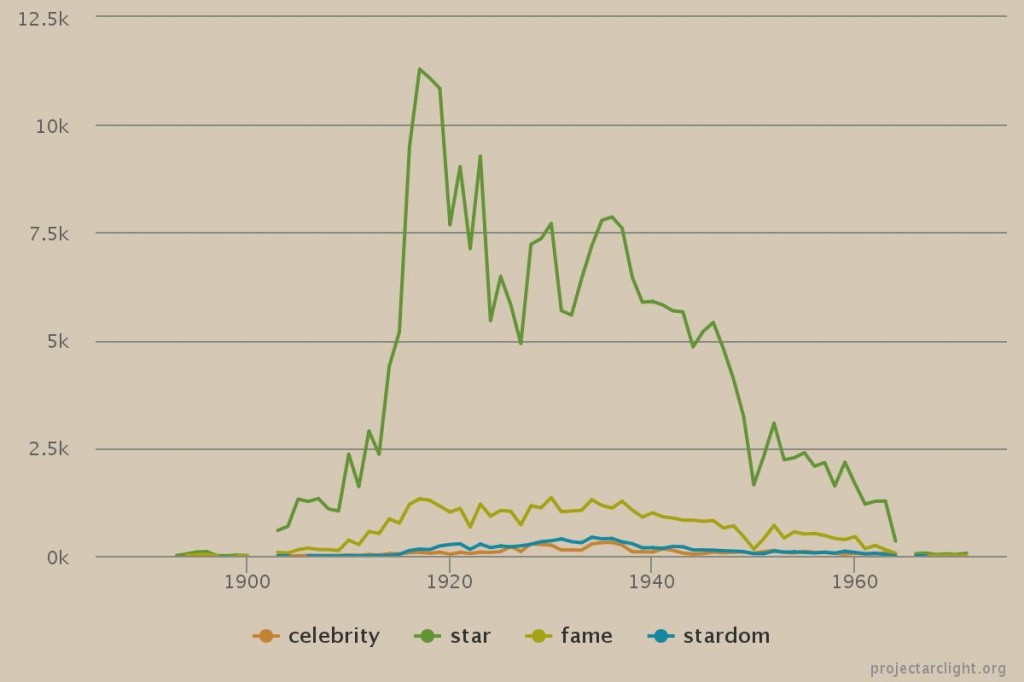
As part of the launch of the Project Arclight app, and the 50th anniversary of the Department of Communication Studies at Concordia University, on October 9, 2015 the Media History Research Centre hosted a talk by Johanna Drucker. Drucker is an internationally recognized scholar across a wide array of fields, such as typography, experimental poetry, and digital humanities. She currently holds the position of Breslauer Professor of Bibliographical Studies at UCLA’s Department of Information Studies. Her most recent publications include Graphesis: Visual Forms of Knowledge Production (2014), SpecLab: Digital Aesthetics and Speculative Computing (2009), and the co-authored book Digital_Humanities with Jeffrey Schnapp, Todd Presner, Peter Lunenfeld, and Anne Burdick (2012).
Drucker’s presentation was entitled “Digital Humanities: From Speculative to Skeptical,” which asked whether or not there was an intellectual future for the digital humanities. Right off the bat she hinted at an affirmative response, although she hesitated to call the digital humanities at present a field or a domain of knowledge defined by a specific core. Drucker described how she came to this realization when she was helping to establish a digital art history institute at UCLA, supported by the Getty foundation. In setting up the institute, queries concerning how the digital is going to change art history and how it will create new types of questions became the focus. These issues, however, Drucker viewed as ancillary to the work that needs to be done.
Urging us to take a critical approach to digital humanities research, Drucker raised a different set of questions, pondering: What are the claims we want to make? Where should the digital humanities sit institutionally? What are reasonable and realistic expectations for digital humanities research? “Deep skepticism,” she argued, “is essential at this point.”
Turning to a brief history of the digital humanities, Drucker reflected on the works of Roberto Busa, Lisa Gitelman, Ben Fry and many others as well as the Rossetti Archive, the Austrian Academy Corpus, the Proceedings of the Old Bailey, and the Homer Multitext. She recounted the early excitement surrounding the development of the digital humanities and explored how it achieved legitimacy in order to secure and validate the amount of energy and resources that goes into it today. She noted, though, that many early digital humanities projects were conceived without a good sense of how they could be utilized, and this limited their impact on scholarship. By contrast, with the Digging into Data Challenge, the task of setting out how to make this information useful became explicit, and certainly this has been a key driving force for Project Arclight. For Drucker, the most productive digital humanities projects provide a way into material, showing you a point of departure rather than making detailed arguments that risk reification. In short, it is not what the project states but what it allows us to ask that might be one of the most valuable contributions of digital humanities.
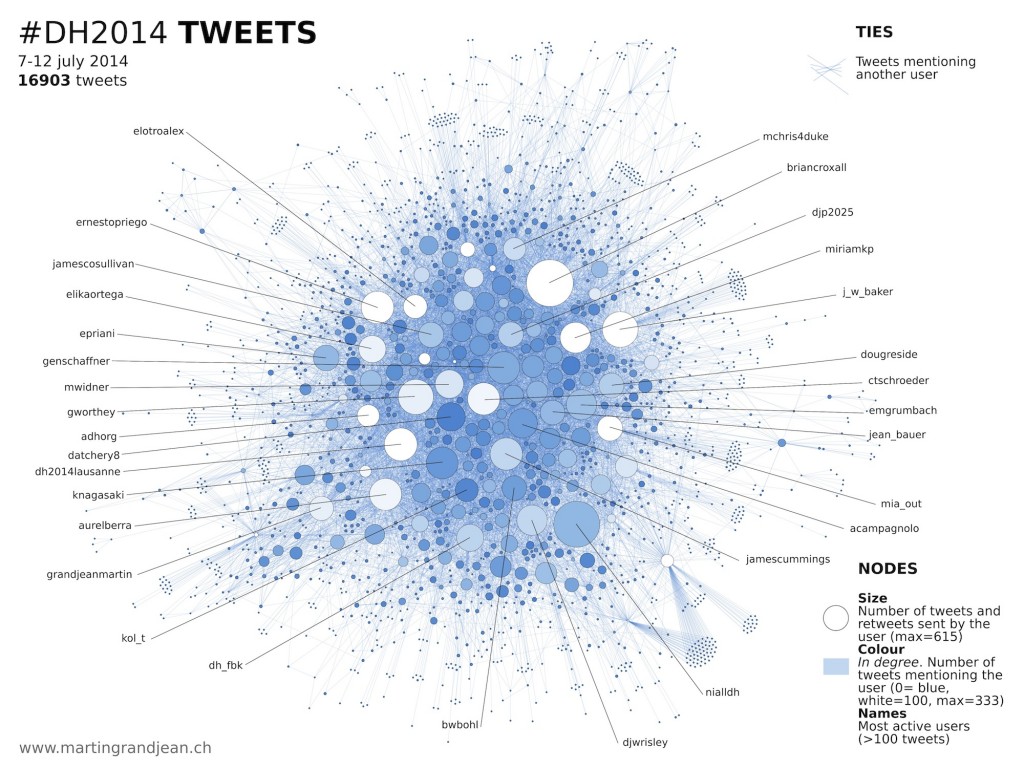
Drucker concluded her talk by identifying key issues she finds problematic in the digital humanities. First, she pointed out that the tools of digital humanists often originate outside the humanities, and as a result are built on different epistemological assumptions. For example, a tool constructed in the natural or social sciences may emphasize the reproducibility of results as the primary goal; yet, this contradicts with the interpretative focus of the humanities where situating findings in a specific socio-cultural and historical context is vital. Thus, in adopting such tools we are not only relying on techniques developed outside the humanities but also the assumptions embodied within the tools. Second, Drucker noted that not many in the humanities have ever taken statistics and are not necessarily proficient in statistical methods. This can become a problem when examining visualizations and network diagrams. While visualizations are informative as an interrogation tool, enabling researchers to see large patterns as well as to detect anomalies, and network diagrams have illustrative value, they are only effective if we know how to read them. Moreover, coming from business and politics, visualization techniques are often premised on factors outside of and of less importance to humanistic inquiry.
Drucker’s main concern is the unexamined epistemological biases and contradictions of adopting these digital tools. As a solution, she suggests we begin with models of knowledge intrinsic to our own work and then build platforms and tools from that base rather than co-opting platforms and tools from other fields. Thus, as digital humanists we need to engage with statistics and critical media studies, understand how to make, manipulate, and comprehend structured data, and create training opportunities for the necessary skill acquisition to undertake digital humanities research. As a closing remark, Drucker asserted that the strength of the humanities lies in its refusal to settle on a singular resolution.
As I left Drucker’s extremely informative talk, new ideas raced through my head and I began to reflect on and rethink my own preconceptions. Importantly, her presentation sparked new imaginings of what the digital humanities could look like in the future and reinforced my perception of the strength of digital tools. Throughout her talk, Drucker asserted that the usefulness of digital humanities work lies in its potential to create entry points into research that otherwise may be hidden, not in its ability to provide answers. This discussion also clarified the dangers and limitations of focusing on answers instead of entry points, notably the reification of information and knowledge. The language of “this is,” Drucker argued, is a game ender, a reification of misreading.
Another crucial distinction Drucker made was between reading and computer processing. Taking issue with the concept of distant reading, Drucker elucidated how machine processing is not reading; rather, machine processing is matching. Every act of human reading, she continued, is a misreading, and “this is our great virtue.” As evident in the articles I have written for Project Arclight and posted on this site, I have found myself intrigued by the catchy concept of distant reading. Drucker’s talk provided an opportunity to reflect on this concept and differentiate between human reading and computer processing. Overall, Drucker reminded me of the importance of remaining inquisitive, skeptical, and self-reflexive in all our scholarship.
References
Austrian Academy Corpus. Web. 19 Nov. 2015.
Burdick, Anne, Johanna Drucker, Peter Lunenfeld, Todd Presner, and Jeffrey Schnapp. Digital_Humanities. Cambridge: MIT Press, 2012.
The Complete Writings and Pictures of Dante Gabriel Rossetti: A Hypermedia Archive. 2008. Web. 19 Nov 2015.
Drucker, Johanna. Graphesis: Visual Forms of Knowledge Production. Cambridge: Harvard UP, 2014.
—. SpecLab: Digital Aesthetics and Speculative Computing. Chicago: U of Chicago P, 2009.
The Homer Multitext. 2014. Web. 19 Nov. 2015.
Old Bailey Proceedings Online. Version 7.2, March 2015. Web. 19 Nov. 2015.