This past March, Eric Hoyt previewed an early version of the Arclight software application at the Society for Cinema and Media Studies conference in Montreal (you can read more about that session, as well as other digital projects at SCMS, here). The Arclight app searches the Media History Digital Library’s corpus of 1.4 million pages of film and magazines, and visualizes the number of hits for searched terms to look at how those terms trend over time. Since SCMS, a number of additions have been made. As progress on the Arclight prototype continues, we wanted to provide an update on where the app currently stands, what it can do, and the work that remains to be done.
Much of the credit for Arclight’s rapid technical development goes to Kevin Ponto, Assistant Professor of Design Studies and faculty in the Living Environments Lab at the University of Wisconsin, Madison. Kevin’s work has resulted in a stunningly fast, flexible, and well-visualized interface. The current version of the software works on a user’s local machine, although a web-based version should be available sometime this summer. Here is the interface as it currently stands:

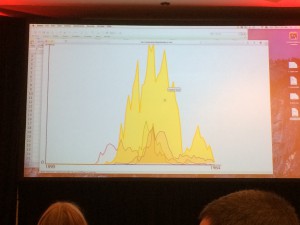
This screenshot shows a Scaled Entity Search for two search strings originally suggested by attendees of the SCMS workshop where Arclight was made public: “propaganda” (in blue), and “public relations” (in red). The graph at right visualizes those results; quantitatively, the y-axis represents the percentage of pages that include the searched entity in a given year (the x-axis).
The interface is already quite user-friendly. The entities to be searched are entered in the “search strings” input field. While this SES only compares two terms, Arclight is capable of searching for more than a thousand quite quickly. Other options are available via checkboxes, and defaults have already been set up to anticipate the needs of most users.
“Literal search,” for example, ensures that two-word entities (like “public relations”) are queried through Lantern as a literal string rather than as an object variable; this helps cut down on false positives significantly. Users comfortable with more ambiguous results can deselect this option. The “Streamgraph” option presents results as a stacked graph (as seen above), where the area of each search term in a given year is proportional to the results for all terms, showing the general prevalence of each. Users can also select a non-stacked representation of the data in the form of an overlapping line graph by deselecting the Streamgraph option:

This configuration may be more useful for users wishing to visualize the absolute rather than relative prevalence of entities. As this example shows, it is particularly effective at visualizing direct comparisons between a small number of entities.
“Normalize,” also on by default, mathematically adjusts the visualization of the page hits based on the total number of pages on the MHDL library for a given year. This ensures that spikes or dips in the visualization that occur due to a particular year having a greater or smaller number of pages are evened out, yielding a more statistically representative representation of the data. As noted below, normalization can be a tricky process, and we are still working out the best way to accomplish it.
In addition to viewing Arclight’s results directly in the app, users can click on the colored portions of the visualization to be taken to the actual Lantern results they represent, for a closer reading. The page hits data is savable as a CSV file via the application’s File menu, as is the visualization itself (as an SVG file). While the interface structure necessary for searching by individual journals is in place, only the corpus as a whole is searchable at the moment; this is the next step of the application’s development. Clearer axis scaling is also on the way.
The above example of “propaganda” vs. “public relations” shows both the power and the pitfalls of the kind of distant reading Arclight was originally designed to accomplish. As we might have expected, the two most obvious spikes in the graph correlate with the World Wars (and a closer look at the hits confirms that they are indeed primarily war-related). We can also see the gradual replacement of the first term with the second in discourses surrounding the use of media as a way to influence public opinion (most clearly in the absolute line graph). However, what explains the first spike, around 1895?
The answer is that it is a statistical anomaly; the spike represents four hits from Billboard in that year. Because the MHDL contains a relatively few number of pages from 1895, the hits on those four pages work out to a relatively large percentage of the corpus from that year as compared with 1918 or 1941. As work on the app progresses, a feature to distinguish between percentage of the corpus and raw page hit data will be incorporated. In any case, Arclight was always intended to bridge the gap between distant and close reading, and the links to specific results in Lantern should help users remain critical about the visualizations it produces.