As with any digital humanities work attempting to balance computational analytics with humanistic concerns, the technical process of SES represents only half of the method. This post deals with the remainder of SES: its interpretive framework.
For those faced with a mass of results output by SES, we propose an interpretive strategy that balances critical understandings of the chosen entities and corpus with knowledge of how digital technologies shape and frame results. The relationship between each of these points is similarly important. This framework can be represented as a triangle (below). We believe attending to each node and relationship within the triangle can keep SES transparent and self-reflexive.
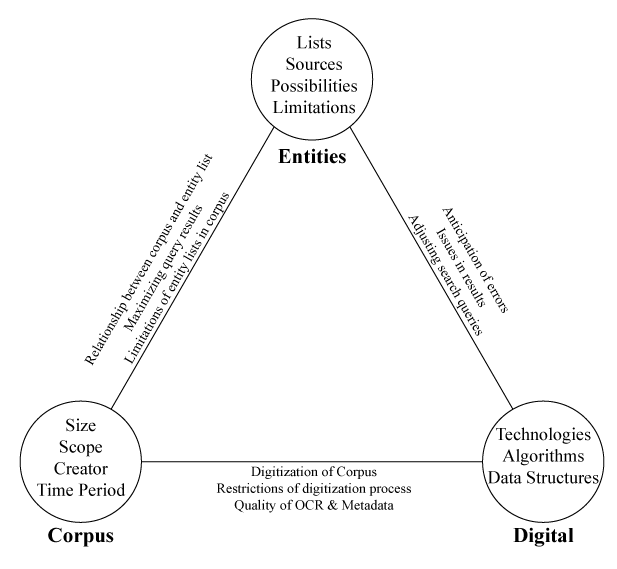
The Nodes and Their Relationships
THE ENTITIES
SES users reflect on how they select their entity list(s). Questions to ask: How and why did you select this grouping to compare? If you did not generate the entity list yourself, where did it come from? What sources were used to generate the data? How does this list open up new possibilities for research? How does it limit or close down other possibilities?
THE CORPUS
SES users reflect on the corpus that is being queried. Questions to ask: What is the size and scope of the corpus? Who created it and why? What are its strengths and weaknesses in terms of the time periods covered and diversity of publications?
THE DIGITAL
SES users reflect on the digital technologies, algorithms, and data structures that comprise the process. Questions to ask: What schema, fields and facets were used in creating the search index? What historical materials, processes, and experiences do not easily lend themselves to digitization and what effect does their omission have on results? How does making materials machine-readable change the research process?
THE ENTITIES-CORPUS RELATIONSHIP
What is the relationship between the list of entities you are querying and the corpus? How could you design an entity list that plays to the strengths of the corpus? At the same time, if we only design research questions and entity lists on the basis of what is likely to generate interesting results in the corpus, how does this limit scholarship?
THE CORPUS-DIGITAL RELATIONSHIP
How did the digitization process change the nature of the corpus? What is the quality of the OCR text? How did intellectual property restrictions and other factors influence what material was digitized and what was left out? How granular is the metadata that describes the corpus and is it consistent? Is the underlying corpus data openly accessible, viewable, and reusable? We contend that it should be to keep the process transparent and repeatable.
THE ENTITIES-DIGITAL RELATIONSHIP
What issues of disambiguation, false positives, and false negatives can you anticipate before querying the entities? What issues do you recognize in examining the queried results? How do you adjust the search queries to try to mitigate these problems? Do you make these adjustments consistently or selectively?
We think of the SES analytical triangle much like an algorithm—an iterative process that researchers can return to again and again as they work. However, we don’t believe that SES researchers need to limit their analysis to this triangle model. The end goal of the SES research process isn’t only to generate meta-commentaries and critiques of all Big Data analysis and visualization. While we believe the triangle model can help researchers interpret their results and qualify historical claims, it can also answer research questions, spark new inquiries, and generate knowledge.