Scaled Entity Search (SES) represents a major development in Project Arclight experimentation. Unlike traditional keyword searches, SES allows users to submit hundreds or thousands of queries to their corpus simultaneously to see where, when, and how often their query terms appear throughout their corpus. Since users can compare their results within a single .CSV—a format that can be fed easily into analytical and visualization programs—SES restores some of the context lost by keyword searches by helping the user to establish and analyze relationships between entities and across time.
Unlike topic modeling and other tools that have been criticized as “black boxes” for their lack of transparency, search-based tools—especially through modifications like visible facets and transparent relevance rankings—have the potential to be relatively well understood by a range of users. Furthermore, considering digital tools’ low rate of adoption—due in part to researchers’ confusion or skepticism regarding their value and operation—search may offer a unique opportunity for negotiating between the promise of big data and the expectations and desires of the majority of academic researchers. For more of the theoretical underpinnings of SES, see the paper we presented at the 2014 IEEE International Conference on Big Data. The remainder of this post will focus on the technical method that we’ve used when developing our prototype.
The SES method uses an Apache Solr search index as its algorithmic backbone. We began testing and improving SES on the pre-existing Solr index of Lantern, the Media History Digitals Library’s (MHDL) search platform. The MHDL’s dataset and Lantern’s index consist of a collection of roughly 1.3 million discrete XML documents representing individual pages from thousands of out-of-copyright trade papers, magazines, and books related to film, broadcasting, and recorded sound. The high-resolution image files are stored at the Internet Archive (which serves as the MHDL’s scanning vendor and preservation repository). We created the page-level XML through XSLT transformation and Python scripting. Each transformed MHDL XML document combines a publication’s metadata (which we wrote in a partially automated process) with the OCR body text of each individual page.
Either before or after building the Solr index, researchers need to generate entity lists—from existing databases or other sources—relevant to the indexed corpus. In some cases, we’ve generated our entity lists ourselves, as in the case of a list of all 2,002 North American radio stations licensed in 1948 (a key year in broadcasting history), which we culled from the relevant Radio Annual. In other cases, we’ve drawn from existing datasets, as when we used Perl and XSLT to output the names of all of the directors included in a pre-existing silent film database developed by other researchers using two volumes of The American Film-Index.
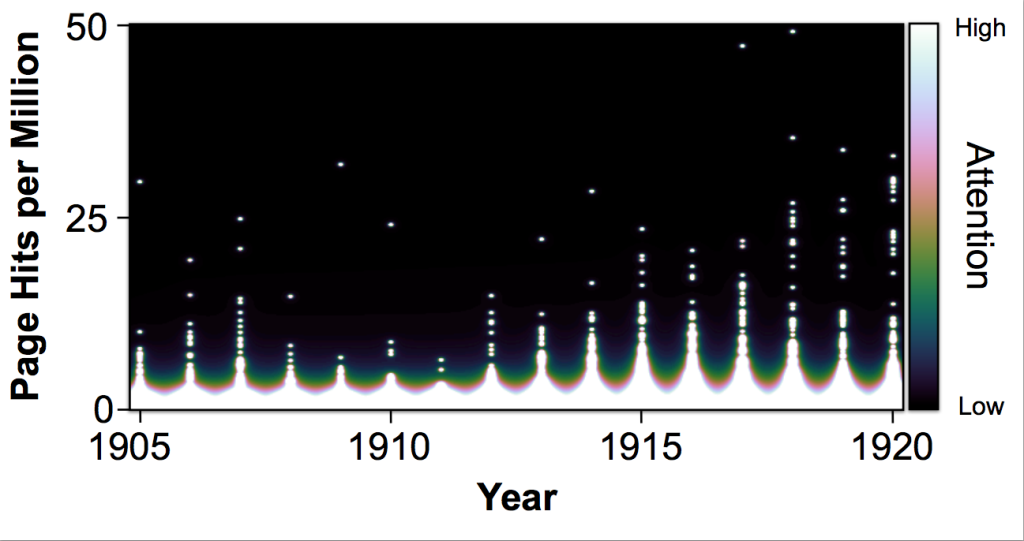
When running SES on lists of names, we recommend pre-processing the entity list to reduce the likelihood of returning false positives or false negatives. Our early cinema dataset, for example, tracked 1,548 names that were credited as having directed at least one film between 1908 and 1920. After looking at the list, however, we noticed that the same individuals were credited slightly differently, resulting in duplicate entries. To generate better results, we wrote queries using the Boolean OR operator to collect all instances of the individual. For instance, we combined the four entities “Al Christie,” “Al E. Christie,” “Albert E. Christie,” “Al. E. Christie” into one query.
Once the indexed corpus and the entity list are finalized, the next step is to create a simple ‘for loop’ that extracts each entity from the list and enters it as a variable into a Solr query in rapid succession. The Solr query can be designed to target the fields and facets that the user finds most interesting. Below is an example of the query automatically generated and run for WCCO, a Minneapolis radio station that we became interested in based on its unexpected prominence in our results:
http://solrindex.commarts.wisc.edu:8080/solr/select?q=\%7B!dismax\%20qf=body\%7DWCCO\&rows=0\&facet=true\&facet.limit=110\&facet.range=year\&f.year.facet.range.start=1890\&f.year.facet.range.end=2001\&f.year.facet.range.gap=1\&f.year.facet.missing=true\&f.year.facet.mincount=-1\&facet.field=title\&stats=true\&stats.field=year
This query returns:
A) the number of matching pages for each entity for every year between 1890 to 2000, B) the titles of books and magazines mentioning the entity and the number of matching pages for any given title, and C) Solr’s StatsComponent, which provides a count of the total number of pages that each entity appears in. To run queries on an entity described by multiple words (like a movie title or person’s name), users need simply to surround their entity with quotation marks.
After running each query, the for loop saves the results locally as an XML file named after the query (“WCCO.xml”). Using an XSLT script, the XML files are converted into CSV files (“WCCO.csv”). Finally, the CSV files are merged into a single CSV file that can be opened and analyzed in R or Excel. Our aggregated CSV file from running SES on the radio station list generated 2,002 rows (each representing a different station) and 113 columns that track the number of matching pages per year, the total number of matching pages, and associated metadata that we had collected for the entities.
 Tracking only whether or not an entity appears on a page (yes/no) on a year-by-year basis may seem like a blunt method for comparing how entities trend over time. Why not count an entity mentioned ten times on a page more highly than an entity mentioned only once? We recognize this potential objection, but we believe the yes/no tracking on a page-by-page basis is useful for a few reasons. First, when applied at scale to 1.3 million pages of text, the distinctions between the amount of attention entities get on a certain page become less important; the outliers and exceptional entities still rise to the top. Second, if a single entity is named multiple times in a single page, then the redundancy helps mitigate the problem of SES missing instances of the entity due to imperfect OCR. Third, the page-level logic of SES makes the process much easier to conceptualize for users who aren’t experts in how search algorithms or logarithmic smoothing work (that is, most of our intended users). Grounding our process in Boolean logic and simple mathematical addition and division helps to keep the method transparent and less like the proverbial “black box.”
Tracking only whether or not an entity appears on a page (yes/no) on a year-by-year basis may seem like a blunt method for comparing how entities trend over time. Why not count an entity mentioned ten times on a page more highly than an entity mentioned only once? We recognize this potential objection, but we believe the yes/no tracking on a page-by-page basis is useful for a few reasons. First, when applied at scale to 1.3 million pages of text, the distinctions between the amount of attention entities get on a certain page become less important; the outliers and exceptional entities still rise to the top. Second, if a single entity is named multiple times in a single page, then the redundancy helps mitigate the problem of SES missing instances of the entity due to imperfect OCR. Third, the page-level logic of SES makes the process much easier to conceptualize for users who aren’t experts in how search algorithms or logarithmic smoothing work (that is, most of our intended users). Grounding our process in Boolean logic and simple mathematical addition and division helps to keep the method transparent and less like the proverbial “black box.”
Once our results are in hand, the next step is analysis. To address humanities concerns with computational analytics, we have devised an interpretive method to accompany SES which we explore in detail in a second post.